


什么是索引?
它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
为什么会诞生索引?
使用索引检索数据会更加快,就好比使用字典中的目录去查询文字一样。
索引的类型
以mysql为例
- 普通索引:目的仅仅为了加速查询,没有限制,值可以是null,值可以重复
- 唯一索引:加速查询(普通索引) + 列值唯一(可以有null)
- 主键索引:加速查询(普通索引) + 列值唯一(不可以有null)+ 表中只有一个
- 组合索引:指在多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
- 全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。不过目前只有char、varchar,text 列上可以创建全文索引。
- 空间索引:是对空间数据类型的字段建立的索引
索引的优缺点
优点是加速查询,缺点是额外占用磁盘空间,数据变动后索引的维护与更新也会更加消耗资源。
聚集索引与辅助索引
在数据库中,B+树的高度一般都在24层,这也就是说查找某一个键值的行记录时最多只需要2到4次IO,这倒不错。因为当前一般的机械硬盘每秒至少可以做100次IO,24次的IO意味着查询时间只需要0.02~0.04秒。
数据库中的B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),
聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息
聚集索引
#InnoDB存储引擎表是索引组织表,即表中数据按照主键顺序存放。
聚集索引(clustered index)就是按照每张表的主键构造一棵B+树,同时叶子结点存放的即为整张表的行记录数据,也将聚集索引的叶子结点称为数据页。
#如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引。
#如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。
#由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。
辅助索引
#辅助索引的叶子节点不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含一个书签(bookmark)。该书签用来告诉InnoDB存储引擎去哪里可以找到与索引相对应的行数据。
#InnoDB存储引擎的辅助索引的书签就是相应行数据的聚集索引键
#每张表上可以有多个辅助索引,但只能有一个聚集索引
#举例来说,如果在一棵高度为3的辅助索引树种查找数据,那需要对这个辅助索引树遍历3次找到指定主键,如果聚集索引树的高度同样为3,那么还需要对聚集索引树进行3次查找,最终找到一个完整的行数据所在的页,因此一共需要6次逻辑IO访问才能得到最终的一个数据页。
索引的数据结构
hash表:具体结构是hash表+链表的组合结构。hash表存储hash值和指向链表的指针,链表存储索引数据。优点是只需要一次hash计算就可以快速找到值,缺点是不适合排序、范围查询、模糊查询以及容易出现hash冲突。
平衡二叉树:具体结构是数据(关键字)+指向两个子节点的指针。每一个节点都存放数据且最多有两个子节点,如果数据量大会导致层级很高,查询叶子节点效率低。且单个节点存储数据少,每次节点进行比较的时候都需要进行一次I/O获取节点的数据(因为两个节点最多两路查找),而在操作系统中,I/O的成本是很高的。
B树(平衡多路查找树):具体结构是数据(关键字)+指向多个子节点的指针
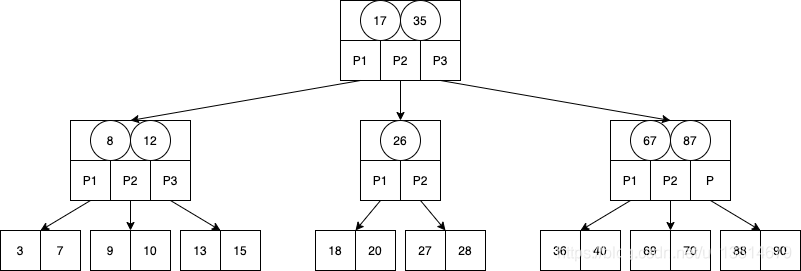
- 关键子用于保存数据
- 查找路径不止两个即不止两个子节点
- 有 k 个子节点的非叶子节点拥有 k − 1 个关键字
- 所有的叶子结点都在同一层
简单来理解就是每一层节点可以拥有的子节点个数增加了,而且每一个节点携带的关键字也增加了(这样才能对应多个子节点)。例如上面第二层的第一个节点,P1指针指向的子节点都是是比 8 小的数据,P2指向的则是大于8小于12的。
优点:
- 每层的节点数增加了,树高也大大减少,这就大大减少了I/O次数
- 读取一个节点的时候可以一次性读取大量关键字数据
- 可以充分利用了磁盘块读写的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来)
缺点:
- 节点既要存索引信息又要存其对应的数据,如果数据大且当树的体量很大时,每次读到内存中的树的信息就会不太够。
- B树相对二叉树虽然提高了磁盘IO性能,但并没有解决遍历元素效率低下的问题。
- B+树:具体结构是关键字+指向多个子节点的指针,只有叶子结点保存数据。
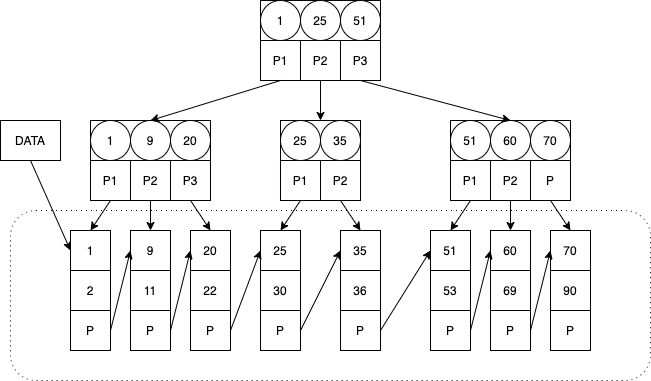
- 有 k 个子节点的非叶子节点拥有 k 个关键字
- 关键字不保存数据,只是用来索引(这样非叶子节点的所占的内存空间就变小了,读到内存中的索引信息就会更多一些,相当于减少了磁盘IO次数)
- 数据都是存在叶子节点,这样保证了相近的数据都能存在同一块数据块里。另外也使得B+树的查询次数更稳定,每次查询次数都是相同的,需要查询到叶子节点
- 叶子节点的指针指向下一个数据对应的叶子节点。因此B+树具备了天然排序功能,在排序和范围查找的时候更方便。
- B+树可以方便地做全表搜索,只需要从第一个叶子节点顺序往后面扫描即可,而B树则需要做树的遍历。
参考资料:https://www.cnblogs.com/Eva-J/articles/10126413.html
版权声明:本文为博主原创文章,欢迎转载,转载请注明作者、原文超链接,感谢各位看官!!!
本文出自:monkeyGeek
座右铭:生于忧患,死于安乐
欢迎志同道合的朋友一起交流、探讨!
 monkeyGeek
monkeyGeek