


垃圾回收器的实现,跟厂商有很大关系。这里主要讨论基于JDK1.7 Update14之后的HotSpot虚拟机。新生代收集器使用的收集器:Serial、PraNew、Parallel Scaveng;老年代收集器使用的收集器:Serial Old、Parallel Old、CMS;以及G1收集器。
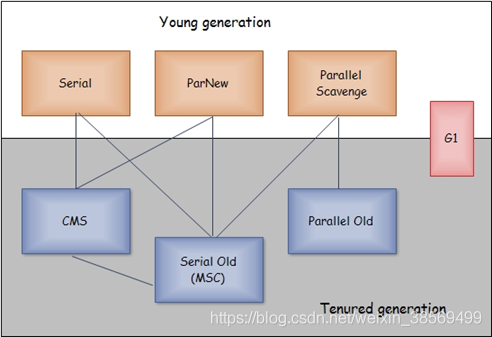
垃圾回收器的分类
- 按照线程数分类
- 串行回收器:同一时刻只有一个回收线程
- 并行回收器:垃圾回收时可以有多个回收线程并行回收
- 按工作模式分类
- 并发收集器:收集线程与用户线程同时执行
- 独占收集器:只有收集线程执行
性能指标
- 吞吐量:用户线程运行时间占总运行时间的比例
- 暂停时间:STW时间
- 内存占用:堆区大小也会影响收集时间
常见概念及技巧
- 如何查看当前的收集器
- 查看命令行参数:-XX:+PrintCommandLineFlags
- 使用命令行指令:jinfo -flag 相关垃圾收集器参数 进程ID
常见GC日志参数
- -XX:+PrintGC输出日志
- -XX:+PrintGCDetails输出详细日志
- -XX:+PrintGCTimeStamps输出时间戳
- -XX:+PrintGCDateStamps输出时间
- -XX:+PrintHeapAtGC在进行gc前后打印出堆信息
- -Xloggc:../../gc.log日志的存放路径
- GCViewer分析工具
- GCEasy分析工具
串型回收器
Serial收集器
1 | 适用于新生代 |
Serial Old收集器
适用于年老代
标记整理算法
其它Serial相同一般Serial+Serial Old可以配合使用
并行回收器
ParNew收集器
适用于新生代
复制算法
多线程收集器
本质上是Parallel Scavenge的增强,为的是更好的与CMS收集器配合使用Parallel Scavenge收集器
适用于新生代
复制算法
多线程收集器:它追求的是达到可控的吞吐量
会产生STW(stop the world)
适用于几十兆到1G内存
参数解析:
1)精确控制吞吐量
-XX:MaxGcPauseMillis参数允许一个大于0的毫秒数,收集器尽可能保证内存回收时间不超过设定值。但是这个时间的缩短是以牺牲吞吐量和新生代空间来换取的,过度缩小会导致垃圾收集更频繁,停顿时间减少,但吞吐量也会降低。
-XX:GCTimeRatio参数的值应该是一个大于0小于100的整数,也就是运行用户代码时间和垃圾收集时间的比例。比如设置为19,表示运行用户代码时间:GC时间=19,所以吞吐量是19/(19+1)。参数默认值是99,也就是99%的吞吐量。
2)收集器还有 “GC自适应调节策略”的开关参数-XX:+UseAdaptiveSizePolicy。参数打开后,不需要指定新生代大小(-Xmn)、Eden与Survivor比例(-XX:SurvivorRatio)、晋升老年代的对象大小(-XX:PretenureSizeThreshold)等细节参数,虚拟机会根据当前系统的允许情况、收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大吞吐量。Parallel Old收集器
适用于年老代
标记整理算法
算法不同,其它与Parallel Scavenge相同JDK 1.8默认的垃圾回收组合就是PS+PO
并发回收器
CMS收集器
目的是尽可能缩短STW
标记清除算法
用于年老代1)初始标记:单线程标记直接与GC Roots关联的对象,速度很快,为了确保准确性需要“Stop the World”;
2)并发标记:与用户线程并发执行,找到所有可达对象并标记,不需要“Stop the World”;
1 | 三色标记算法 |
3)重新标记;多个垃圾回收线程并行执行,用于修正在并发标记阶段怀疑是垃圾的那一部分对象。需要“Stop the World”;
4)并发清除:不需要“Stop the World”
CMS收集器的缺点:
1)对CPU资源敏感(并发会占用cpu资源)
2)CMS无法处理浮动垃圾(并发标记阶段由于用户线程在执行产生的垃圾)
3)基于标记-清除算法,收集结束会产生大量空间碎片
4)重新标记阶段可能出现较长gc时间
G1收集器
面向服务端应用的收集器适合大内存
一款并行与并发收集器
能建立可预测的停顿时间模型
不需要和其他收集器配合
每次根据允许的最大回收时间,优先处理回收价值大的区域分区region
- 将整个堆划分为2048个大小相同的区域
- 每个region在1到32m之间
- 在整个jvm周期内分区大小不变
- 每个分区只可能属于Eden区,幸存者区,老年代区等一个角色,后续有可能发生角色转换
- humongous区是新增的区域类型,用于存储大对象,当对象大于1.5个region时会转化。h区可以是连续的,用于存储大对象
G1收集器的主要回收过程
- 年轻代GC
- 采用并行的独占式收集方式处理年轻代
- 首先发生STW
- 然后创建回收集,包括eden区和survivor区
- 采用复制算法将存活对象复制到另外的survivor区和old区
- 老年代并发标记了
- 当堆内存达到45%的使用率时
- 混合回收(full gc依然存在,作为回收评估失败的保护机制)
- 年轻代和老年代一起回收,存活的年轻代region对象将被复制到另一个年轻代区域,老年代region也将被复制到另一个空闲区域
- 记忆集与写屏障
- 记忆集Remembered Set
- 产生的原因:当需要回收某区域时需要扫描谁引用了本区域对象,那么有可能来自年轻代,老年代等,因此如果全局扫描性能太差
- 解决办法:每一个region都有自己对应的记忆集,用于记录是谁引用了本区域对象
- 记忆集Remembered Set
G1回收器优点:
1)空间整合:
G1从整体看是基于标记-整理算法(对不同的分区进行空间整理)实现的收集器,从局部看是基于复制算法(例如将eden区幸存对象复制到幸存者区)。这两种算法都意味着G1运行期间不会产生大量内存空间碎片。2)可预测的停顿:
降低停顿时间是G1和CMS共同关注的,但G1能建立可预测的停顿时间模型,让使用者明确指定在一个长度为M毫秒的时间片段内,GC的时间不得超过N毫秒。3)有计划的垃圾回收:
G1可以有计划的在Java堆中进行全区域的垃圾收集。G1跟踪各个Region里面的垃圾堆的价值大小(回收所获得的空间大小,以及回收所需要的时间),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region。这就是Garbage-First的由来。ZGC
- 目标是在保证吞吐量的前提下实现延迟在10ms内
- 基于分区回收
- 基于标记整理算法
Shenandoah
- openjdk开发
- 低延迟
- 高负载下吞吐量下降
Epsilon
- 只负责内存分配,不负责回收
- 主要用于虚拟机开发人员调试
参考资料:
[1]https://blog.csdn.net/weixin_38569499/article/details/85645867
版权声明:本文为博主原创文章,欢迎转载,转载请注明作者、原文超链接,感谢各位看官!!!
本文出自:monkeyGeek
座右铭:生于忧患,死于安乐
欢迎志同道合的朋友一起交流、探讨!
 monkeyGeek
monkeyGeek